
Why and who should read this article: This article is for readers who are looking for a brief summary of system design concepts, as a reference for interviews, project needs, or a general curiosity.
What are key features of distributed systems:
- Scalability: Scalability helps to meet the increased demand.
- Horizontal scaling: it can be achieved by adding more servers to the existing infrastructure. Examples are MongoDB and Cassandra DB that are horizontally scalable by adding more servers.
- Vertical scaling: it can be achieved by adding more resources (like CPU, RAM, etc.) to the same servers. An example is MySQL that can be scaled by switching it from smaller to a larger capacity machine.
- Reliability: If I can be confident that the system will always succeed to serve the needs at all the time, I will call it a reliable system. For example, I can rely on my email system that it will always be available. Even if some of the services might fail, it is still reliable.
- Availability: Availability means a system is operational in the time period. If a system has no downtime, it could be 100% available. Note: A system may be available but may not be reliable. For example, my email is available to use but what if it has a security issue? If it has a security issue, I will not rely on it to keep my emails secured.
- Efficiency: Being efficient means the system works in a right way.
- Effectiveness: Being effective means the systems provides output within the accepted quality and quantity.
- Manageability: A system is manageable or serviceable if it can be repaired within the defined criteria.
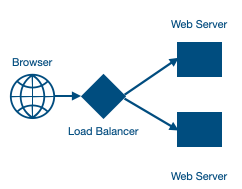
What is a Load Balancer and how it distributes the traffic:
- A Load Balancer helps in managing the traffic on servers. If a server is busy or if a server is not responding, the load balancer can route the traffic to another server. There are many ways to design the architecture using load balancers at the right place. For example, we can have load balancer before web servers, we can have it between middle layer/application servers or before the databases.
- Load Balancing algorithms: Load Balancers have algorithm options to decide how to choose a server to send a requests to serve. Below are some of the options:
- Least connection method
- Least response time
- Least bandwidth method
- Round robin
- Weighted round robin
- IP hash
What are Redundancy and Replication concepts:
- Redundancy is a way to avoid fault tolerance. In simpler terms, let’s say we have two web servers serving the traffic. What if we keep a third web server on a stand by mode? If by any chance one out of two web application servers fails to serve the traffic, we can utilize the third web application server with the failed web server. This third web server is a redundant server. I can recall my personal experience when one of two web servers failed. It was easy to utilize the standby/redundant server within an hour. It’s possible to plan for it without waiting for an hour.
- Replication is a way to ensure the redundant servers are in sync. In the above example. what if a server fails but the redundant server is not up-to-date with the data/files on main traffic serving web servers? To avoid such a situation, it’s advisable to ensure such a redundant server has same information as other servers. Another common example is a database replication from a primary to a secondary database. In my experience, a server failed but the redundant server was not ready. It happened because the script responsible for the replication failed. To prevent such a failure of a replication, an automated period health and data check of replicated servers is important. Periodic dry-run of such a change process is recommended. As Benjamin Franklin said, “Failing to prepare is preparing to fail.”
What is Caching: and how it works:
Cache is a way to store data in memory for a defined period. This helps to access data faster. One simple example is HTTP session. In a web application architecture, we can keep the commonly asked data into cache. Other related information:
- Cache helps in reducing latency and increasing throughput.
- Content Delivery Network (CDN) systems use static media files. Generally, web applications use CDNs to store static media files. A CDN could be using a light weight HTTP server using NGINX. CDN is a network of servers that distributes the content from original server to multiple locations by caching the content closest to the users’ locations.
- Cache invalidation: It’s important to plan for cache invalidation when theta is changed at the source (like a database). There are different ways to do it:
- Write-through cache: this technique suggest to write the data in the cache at the same time when the data is written to the database. This prevents any data sync issue. But this increases latency of write operation as it has to write data twice.
- Write-around cache: this technique suggests to just write the data to the storage (like a database) and not to write to the cache. When the data is accessed, it will take time.
- Write-back cache: this technique suggests to write the data only in cache, not in the storage. After the end of a time period or conditions, data is saved into the storage. This has the side effect of missing the data from cache, if there is a crash in the servers string the cache data.
What is data partitioning:
Definition: It is a process of splitting the data into multiple small parts. After a certain point, it is better to scale horizontally, by adding more machines. Below are some ways to partition the data:
- Horizontal partitioning: It is also known as data sharing. We put different rows into different tables. It could be done based on a range.
- Vertical partitioning: In this type of partition, data table is divided vertically. For example, data can be stored in one DB server and images can be stored in another DB server.
- Directory based partitioning: In this approach, partitioning plan can be stored in a look up service.
What are Partitioning criteria:
For more about partitioning, refer here. Below are brief notes:
- Range based partitioning: This approach assigns rows to partitions as per a range. For example, I partitioned a MySQL DB table by months so that the database performance is optimized.
- Key or hash based partitioning: this approach partitions the data with hash code on a key field. But hash based can be problematic to further expand in the future. So, using consistent hashing is recommended.
- List partitioning: This is similar to range. In this approach, we partition the data based on a list. For example, we can partition based on region or based on a language preference.
- Round-robin partitioning: In this approach, new rows are assigned to a partition on a round robin basis.
- Composite partitioning: It combines more than one partitioning approaches. For example, we can first apply list partitioning and the hash partitioning.
What are the problems with data partitioning:
- Joining database tables can be performance inefficient. To avoid it, try to denormalize data in a way that avoids data cross-joins.
- Data partitioning can cause referential integrity. To avoid it, store the referential integrity logic in application code.
- Schema changes are difficult with data partitioning. To avoid it, use directory based partitioning or consistent hashing.
When to use data partitioning:
We should use it when it is not possible to manage the data within a single node or a performance improvement is necessary.
What is a proxy server:
When a client sends a request, the first server that receives the request could be a limited, light-weight server. This light-weight server can further pass the request to the actual backend server. Such a first server is called a proxy server. It could be a hardware or a software. A proxy server acts as a firewall.
Advantages/usages of proxy servers:
- Logging the requests.
- It can also help in caching the responses.
- Serving a downtime message when required.
- Proxy server helps to add the security to the backend server.
- Blocking some websites for the users within a company. Proxy server can also be used to bypass the restriction of a website for a company users.
Here are some types of proxy servers:
- Open proxy: An open proxy is accessible by any user on internet. It can be anonymous (that hides the identify of the originated machine) or a transparent (show the identity of the originated machine).
- Reverse proxy: A reverse proxy is for the server to get the response from other servers and send the response to the client. A Load Balancer is a use case of a reverse proxy.
What is a Heartbeat for systems:
In a distributed systems architecture, we need to know if other servers are working. To achieve it, we can have a centralized monitoring system that can get the uptime status of each server. We can decide the steps if a server is not working as expected.
What is a checksum:
Checksum is a way to ensure the data transferred from one system to another system is as expected. Checksum is calculated and stored with the data. To calculate the checksum, a hash function like MD5 can be used. Source and destination servers can match the checksum to ensure data is transferred from the genuine source.
What is quorum:
In a distributed system, a quorum is a process to ensure all required systems have the same information and it only completes a transaction complete when all systems have the needed information. For example, if we have three database servers. If we want to ensure that a transaction is only considered complete when all three databases instances get the same information and agree to the transaction. Quorum can help to ensure such an operation.
What is the Bloom filter:
Bloom filter is a data structure approach to quickly find an element in a set. Bloom filter structure informs if an element MAYBE in a set or DEFINITELY not.
How HTTP works: A user hits a URL on the browser. We use either http or https protocol. Second is a domain (like http://www.abc.com). We use a DNS (Domain Name Service) lookup to look for an IP for a domain. DNS information is generally cached. To look for a DNS, we have DNS servers. Finally a browser has the IP address of the server. Next, the browser get a TCP connection with the server. Browser sends a request to the server. Server sends an http response to the browser. Browser parses the responds and shows the response to the user on the browser.
Bare metal infrastructure: this is a term used for legacy physical server infrastructure. When an application needs the highest level of security, bare metals could be the most appropriate solution.
Virtual machines: This uses a hardware that is shared for multiple virtual servers. We use a hypervisor underneath guest OSs. The downside is that these could be vulnerable by noisy neighbor problems.
Containers: it’s a light weight stand alone package. We use a hardware and host OS. On top of it, a container engine is installed. On top of container engine, multiple containers are deployed. Containers are scalable and portable. Containers are less secured. They are vulnerable to security issues at OS level. To avoid security issues, we can run containers inside virtual machines.
Thank you for reading it. As I learn more, I will revise it.
References:
- http://www.openlearningworld.com/books/Fundamentals%20of%20MIS/SYSTEM%20CONCEPTS%20&%20CONTROLS/System%20Efficiency%20and%20Effectiveness.html
- https://lethain.com/introduction-to-architecting-systems-for-scale/
- Caching: https://en.wikipedia.org/wiki/Cache_(computing)
- Data partitioning: https://medium.com/must-know-computer-science/system-design-sharding-data-partitioning-b7201596aafa
- Data partitioning: https://dev.mysql.com/doc/mysql-partitioning-excerpt/5.7/en/partitioning-types.html
- Round-robin data partitioning: https://help.sap.com/viewer/6a504812672d48ba865f4f4b268a881e/Cloud/en-US/c343b0b3bb5710148d80bdb45015f765.html
- Database sharding: https://www.acodersjourney.com/database-sharding/
- https://www.cloudflare.com/learning/cdn/what-is-a-cdn/
- Youtube videos by ByteByteGo authors
